Resolving Concurrency Issues in a Ticketing System with Optimistic Locking 2 (Feat. DB Connection Pool)
Introduction
I thought I had successfully resolved the issue using optimistic locking,
but when actually integrating with MySQL, concurrency control did not work properly in practice.
Below is a summary of the results when 10 users simultaneously requested to purchase 3 tickets using K6.

Except for one user, all failed.
Curious, I then tried a test where 50 users competed for 3 tickets.

Despite the increased contention, when testing with 50 users, it succeeded.
Seeing these results raised several questions:
- Why does optimistic locking, which worked correctly in the test code, fail for all but one user?
- Why does increasing the number of concurrent requests actually lead to success?
Main Content
Issue #1 - Marked as Rollback-Only
Looking through the server logs, I found some clues.
Below is a snippet of logs from the test with 10 users and 3 tickets competing.

“JDBC transaction marked for rollback-only (exception provided for stack trace)”
It showed the transaction being marked for rollback.
Looking at the ticket purchase transaction code:
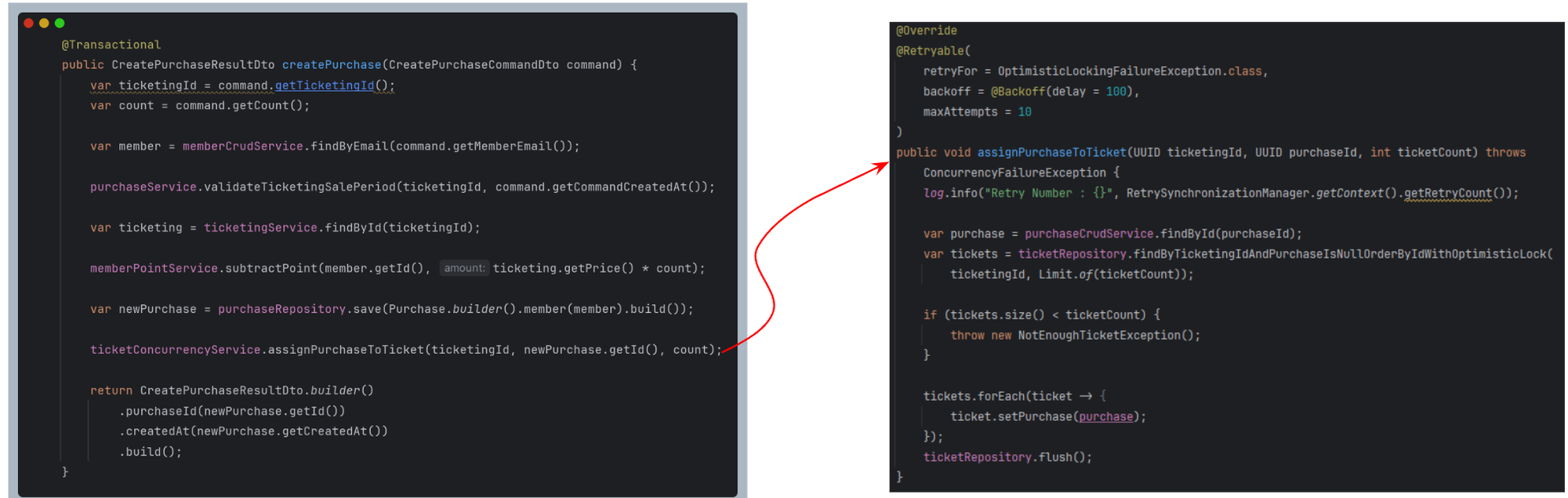
I had assumed that the only situation in which the transaction would roll back was when all retries were exhausted and OptimisticLockingFailureException was propagated to the callee method createPurchase.
But the logs indicated otherwise.
According to the logs,
on the very first retry attempt, the transaction was marked rollback-only, and even if subsequent retries succeeded,
the result would still be a rollback.
Reason: Try-Catch inside Transaction
The reason was found in Wait, why does this roll back?.
TL;DR
Even if you handle exceptions in a try-catch block, if a RuntimeException occurs inside the transaction, the transaction is marked rollback-only.
Even when using the @Retry annotation, it fundamentally relies on try-catch, so OptimisticLockingException and ConcurrencyFailureException, both extending RuntimeException,
will contaminate the transaction.
Issue #2 - Retry Counts
The second issue was the consumption of retries.

Observing the retry counts, I confirmed that all threads used up all assigned retries.
No matter what value was set for the retry count, all opportunities were consumed,
and the total test time increased linearly with the number of retries.
Reason: Transaction Isolation Level
The reason why it worked in the test code but failed in production was transaction isolation level.
In MySQL, the default transaction isolation level is REPEATABLE_READ.
In H2, the default is READ_COMMITTED.
With REPEATABLE_READ, you can only see data from transactions committed before yours started, using undo logs.
Even if retries are performed, it can’t read data committed by other transactions.
No matter how many retries are attempted, a transaction that once failed in contention
will keep seeing stale data and continue to fail.
Without maxAttempts, this could lead to an infinite loop in extreme cases.
Solution to Issue #1 and #2
To resolve both issues #1 and #2 together,
you either need to start a new transaction on each retry
or create a new transaction per purchase request.
The simplest approach was to move the @Retry annotation to the upper callee method:
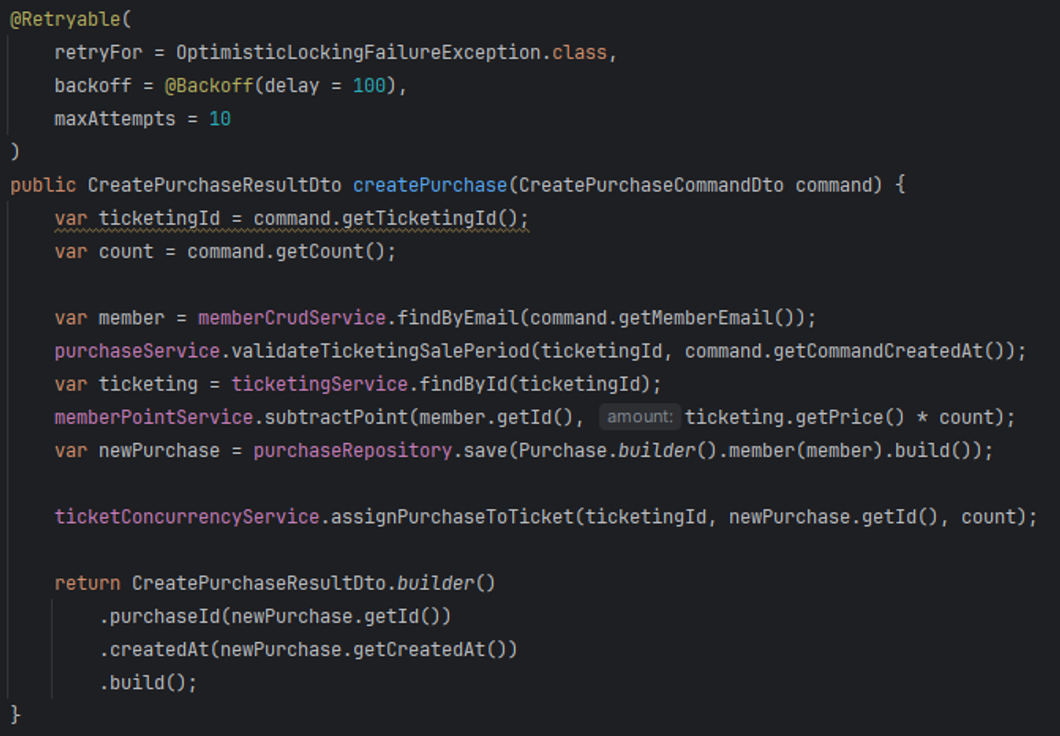

Ultimately, to resolve this issue while maintaining common concerns across different locking strategies and separating changes,
you can refer to this post.
Issue #3 - Different Results Depending on Contention?
In fact, after solving #1 and #2, there were no more functional issues, but one mystery remained.
That is, even without applying any fixes, if you increased the number of users making requests, the purchases completed successfully.
(This was the most perplexing issue that caused the most headaches.)
To investigate, I gradually increased the number of users to see at what point it started succeeding,
and tested repeatedly.

Strangely, starting from 10 and increasing to 11, 12, and so on, the number of successful users increased.
This was a hard-to-accept result, so I dug into the logs again.
(The logs here have been reconstructed for clarity.)

Intuitively, all but one should fail, but this was not the case.
While examining the logs, I noticed something unusual.
Transaction 11 (exec-11) did not start until transactions 1–10 had completed.
(The image is presented sequentially for clarity,
but the actual logs were so jumbled it was very hard to decipher 😅..)
I wondered why transactions were executing in batches of 10,
and the database connection pool came to mind.
Sure enough, upon investigation, the default pool size for the JDBC connection pool we were using, HikariCP, was 10.

I updated the HikariCP pool settings in Spring’s application.yml and tested again.
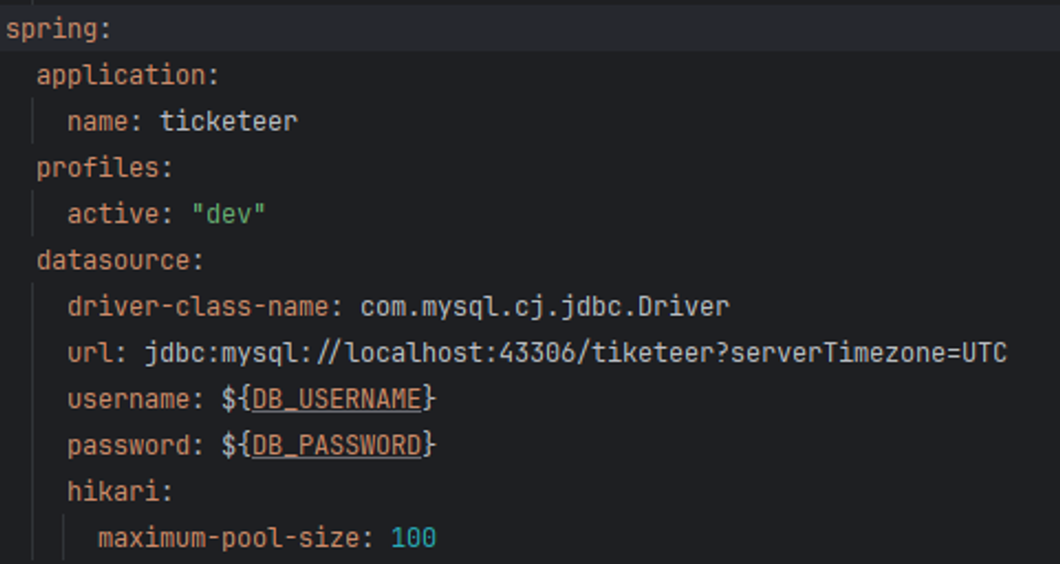

As expected, I confirmed that all but one user failed!
When the connection pool was set to 10, the scenario worked as follows:

Conclusion
In this post, I discussed the causes and solutions to three problems.
The key topics are:
- Try-Catch and Rollback-Only
- Differences in transaction isolation levels
- Database connection pools
While the reasons seem simple in hindsight, each was difficult to identify when first encountered.
Personally, the lessons I learned from this troubleshooting were:
- The importance of understanding database and JPA internals accurately
- The value of proactive log debugging
- (and the need for detailed logs to do so)
- Avoid blindly trusting test code
댓글남기기