K6 테스트를 통해 다양한 동시성 문제 해결책의 최적값 찾기
서론
저희는 티케팅 시스템에서 발생할 수 있는 동시성 문제를 해결하기 위해 다양한 해결책들을 찾아보았고,
아래의 세 가지 방식을 통한 동시성 제어 방식을 구현하였습니다.
- 낙관적 락
- 비관적 락
- 분산 락
일반적으로 퍼져있는 사실은 “경합이 강하지 않은 상황에서는 낙관적 락이 유리하다” 입니다.
하지만 과연 그럴까요?
“경합이 강하지 않은” 이라는 표현은 어떤 기준치를 가진 걸까요?
저희는 직접 테스트 시나리오를 작성하여 상황별로 어떤 락 방식이 동시성 제어에 유리한지 직접 실험해보고, 결과를 분석해보기로 하였습니다.
본론
시나리오를 세분화하기 위해서 티켓팅이 이루어지는 상황에 대한 변수를 찾아보기로 하였습니다.
공통 요인
가장 먼저 공통적인 변수로 티케팅을 시도하는 인원의 수와 남아있는 티켓 매수 두가지를 선정하였습니다.
락 종류별 변수
낙관적 락
낙관적 락을 사용한 동시성 문제 해결 방법의 핵심은 VERSION 칼럼의 불일치에 대해서 발생된 예외를 개발자가 직접 핸들링하는것입니다.
일반적으로 try - catch 문을 통한 예외 처리를 통해서 재시도를 요청하는 방식으로 구현됩니다.
저희 프로젝트의 경우, 스프링의 @Retry 애노테이션을 활용하여 재시도를 요청하였습니다.
@Override
@Retryable(
retryFor = OptimisticLockingFailureException.class,
backoff = @Backoff(delay = 100),
maxAttempts = 10
)
public void assignPurchaseToTicket(UUID ticketingId, UUID purchaseId, int ticketCount) throws ConcurrencyFailureException {}
해당 코드에는 변인이 두가지 존재합니다.
바로 재시도 가능한 최대 횟수를 의미하는 maxAttempts와 재시도간 간격을 의미하는 backoff 입니다.
이 두 값을 시나리오별 최적의 값을 찾기 위해 변인에 추가하였습니다.
비관적 락
비관적 락의 경우, 별도의 변인은 존재하지 않습니다.
분산 락
분산 락을 구현하기 위해서 저희는 Pub/Sub 의 방식을 지원하는 Redisson 라이브러리를 사용하였습니다.
Redisson를 활용한 분산락은 락을 반환할 경우, 구독중인 클라이언트들에게 알려주는 방식을 사용합니다.
// CreatePurchaseWithDistributedLockUsecase.java
@Service
public class CreatePurchaseWithDistributedLockUseCase extends CreatePurchaseUseCase {
private final RedissonClient redissonClient;
public CreatePurchaseResultDto createPurchase(CreatePurchaseCommandDto command)
{
var ticketingId = command.getTicketingId();
String lockName = ticketingId.toString();
RLock rLock = redissonClient.getLock(lockName);
long waitTime = 10L;
long leaseTime = 3L;
TimeUnit timeUnit = TimeUnit.SECONDS;
// 10초 동안 기다리고 3초 안에 반환한다는 의미
try {
boolean available = rLock.tryLock(waitTime, leaseTime, timeUnit);
if (!available) {
throw new TicketConcurrencyException();
}
super.createPurchase(command);
} catch (InterruptedException e) {
throw new TicketConcurrencyException();
} finally {
rLock.unlock();
}
}
}
락을 획득하기 위해 기다리는 시간인 waitTime과 반환할때까지 걸리는 시간인 leaseTime을 변인으로 설정하였습니다.
정리
정리하면, 총 변인은 6가지입니다.
- 공통 요인
- 티켓 수
- 사용자 수
- 낙관적 락
- backoff
- maxAttempts
- 분산 락
- waitTime
- leaseTime
실험 방법
특정 시나리오에서 갖는 최적의 락과 그에 따른 설정값들의 최적값들을 찾기 위해서 시나리오별로 테스트를 진행하였습니다.
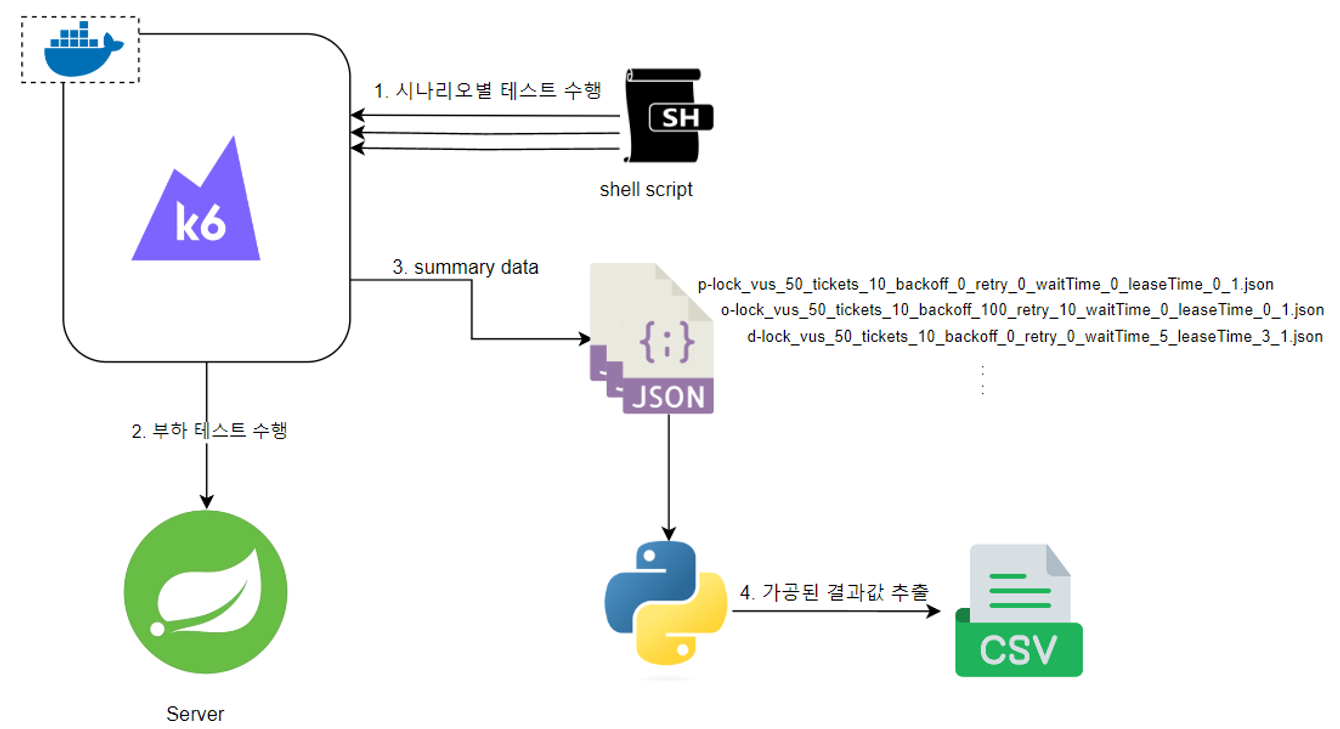
각 변인당 3가지의 값을 설정하고 모든 조합에 대해 실제 부하 테스트를 K6를 수행할 수 있도록 쉘 스크립트를 구성하였으며,
결과값을 파이썬 스크립트를 통해 취합하였습니다.
실험 과정의 간단한 다이어그램은 다음과 같습니다
초기값 선정
리소스 및 시간의 한계로 변인들에 대해서 가능한 모든 값들을 직접 테스트하기는 어려웠습니다.
6가지의 변인에 대해서 각 변인당 3가지의 값들에 대해서만 테스트 하더라도, 3^6 = 729 가지로, 하나의 테스트 당 30초가 걸린다고 가정했을 때 약 6시간(..)의 소요가 걸립니다.
따라서 각 변인당 최대 3가지의 값을 설정하여 테스트하는것으로 결정하였습니다.
공통 인자
- 티켓 수 티켓의 수는 10 / 100 / 1000 의 3가지 값으로 결정하였습니다. 극소규모 / 소규모 / 중규모의 실제 티케팅 크기를 상정하였습니다.
- 요청 유저 수
유저의 수는 10 / 30 / 50 으로 결정하였습니다.
티켓팅 시 일반적으로 예상되는 총 트래픽 양보다 훨씬 작은데, 그 이유는 대기열 시스템을 도입하였기 때문입니다.
모든 신청자들의 요청에 대해서 직접 경합이 이루어지는것은 비현실적이고 성능적으로도 불리할 것으로 예상하였습니다.
전체 서버 앞단에 대기열 큐를 두어 10 / 30 /50 명씩 입장시키고 해당 인원들에 대해서만 동시성 경합이 이루어지는 상황을 가정하였습니다.
낙관적 락
-
backoff
낙관적 락을 사용해 동시성 문제를 해결한 대부분의 레퍼런스들은 재시도 간격 (backoff)에 고정된 값을 할당합니다.
저희는 해당 방식이 random backoff를 통해 성능적으로 개선이 가능할 것이라고 예상하였기에, minBackoff와 maxBackoff, 상/하한을 두고 두 값 사이의 랜덤값을 재시도 간격으로 사용하는 방식을 사용하였습니다.
그렇다면 최소 간격과 최대 간격은 어떤 기준을 두고 정하면 좋을까요?
최소 시간의 경우, 일단 재시도를 시도하는 동안 트랜잭션이 종료되지 않을 경우 어차피 재시도는 실패할 것이라고 생각하여 트랜잭션의 평균 수행시간보다는 큰 값을 설정하는것으로 결정하였습니다.
트랜잭션의 평균 수행시간은 MySQL의 performances_schema 테이블 내부의 transactions_summary_global_by_event_name을 참조하면 얻을 수 있습니다.
간단한 쿼리를 통해서 초단위의 평균 수행시간을 얻어냈습니다.
SELECT
EVENT_NAME,
COUNT_STAR AS total_transactions,
SUM_TIMER_WAIT AS total_time_picoseconds,
SUM_TIMER_WAIT / COUNT_STAR AS average_duration_picoseconds,
(SUM_TIMER_WAIT / COUNT_STAR) / 1000000000000 AS average_duration_seconds
FROM
performance_schema.events_transactions_summary_global_by_event_name

다양한 변인들을 기준으로 테스트를 수행했을 때의 평균 트랜잭션 값은 약 170ms 정도로 관찰되었고 minBackoff 값은 200ms 로 결정하였습니다.
maxBackoff 의 경우는 재시도 시간이 1초 이상일 경우 트랜잭션 종료 후 남는 시간이 너무 클 것이라고 판단하여
임의로 300 / 450 / 600 의 값을 설정하였습니다.
- retry 재시도 횟수의 경우 지침으로 삼을 수 있는 값을 찾기 어렵다고 판단하여 임의의 값으로 설정하였습니다. 30 / 60 / 90 다만, 정합성을 보장할 수 있도록 일정 성공률 이상의 값 중 최소값을 차용하기로 결정하였습니다.
분산 락
- waitTime 분산 락에서의 변인 중 하나인 waitTime은 락을 요청했을때의 최대 대기시간을 의미합니다.
- leaseTime leaseTime은 락을 보유하고 있을 수 있는 최대 시간을 의미합니다.
waitTime과 leaseTime의 초기값 선정배경은 다음과 같습니다.
- waitTime이 leaseTime보다 현저하게 낮을경우, 실패율이 증가할것이라고 예측하였습니다.
- 위 이유로 어느정도의 선형적 비례관계를 유지하고, 일정 성공률을 넘는 최소 값을 차용하는것으로 결정하였습니다.
최종적으로 선정된 초기값은
- leaseTime : 3 / 5 / 7
- waitTime : 5 / 10 / 15
입니다.
결론
실행 결과
전체 실행 결과는 첨부파일에서 찾아보실 수 있습니다.
분석
💡 conflict_rate = tickets / vus (경합도)
비관적 락
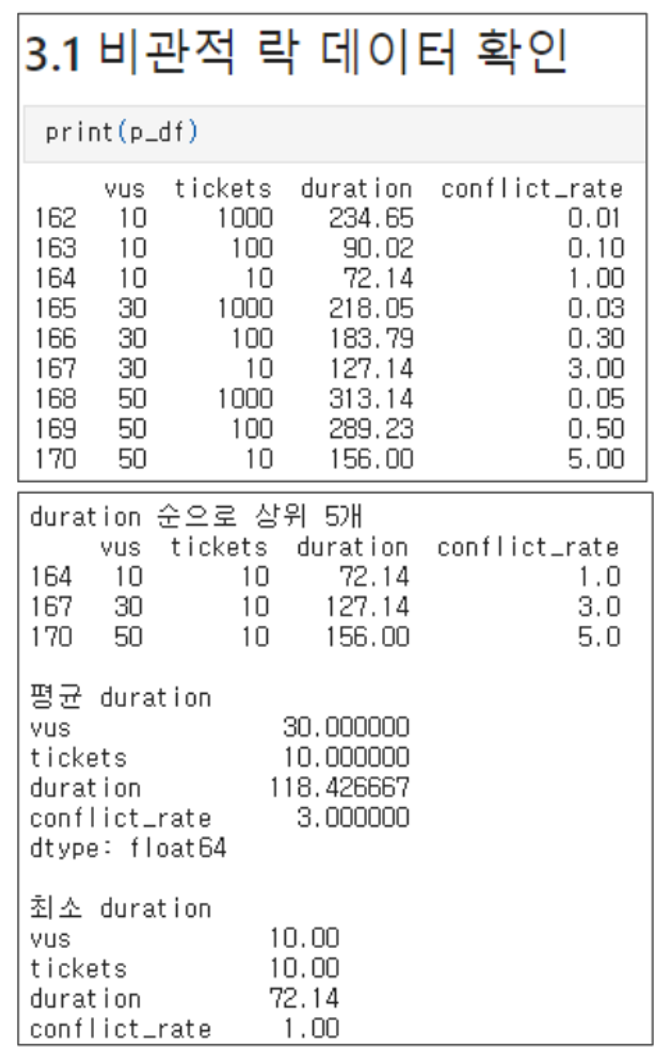
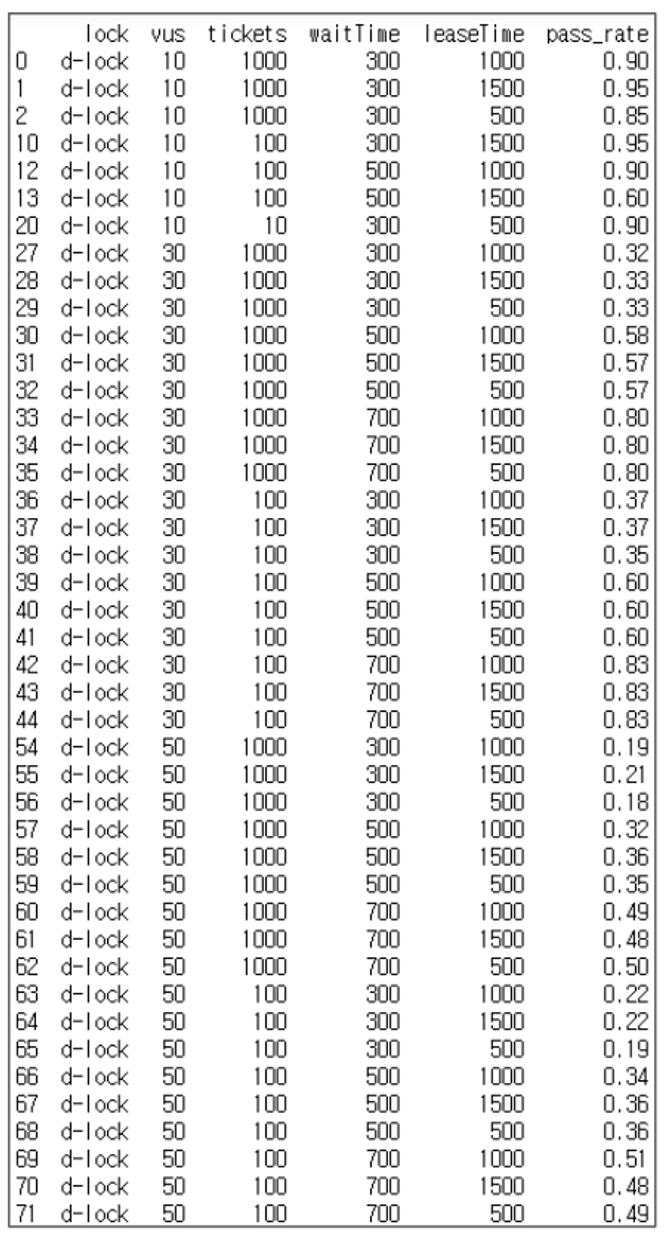
비관적 락의 실행 결과입니다.
특별한 변인이 존재하지 않지만, 경합도(티켓 대비 유저 수)가 증가할수록 duration값이 증가하는것을 확인할 수 있습니다.
낙관적 락
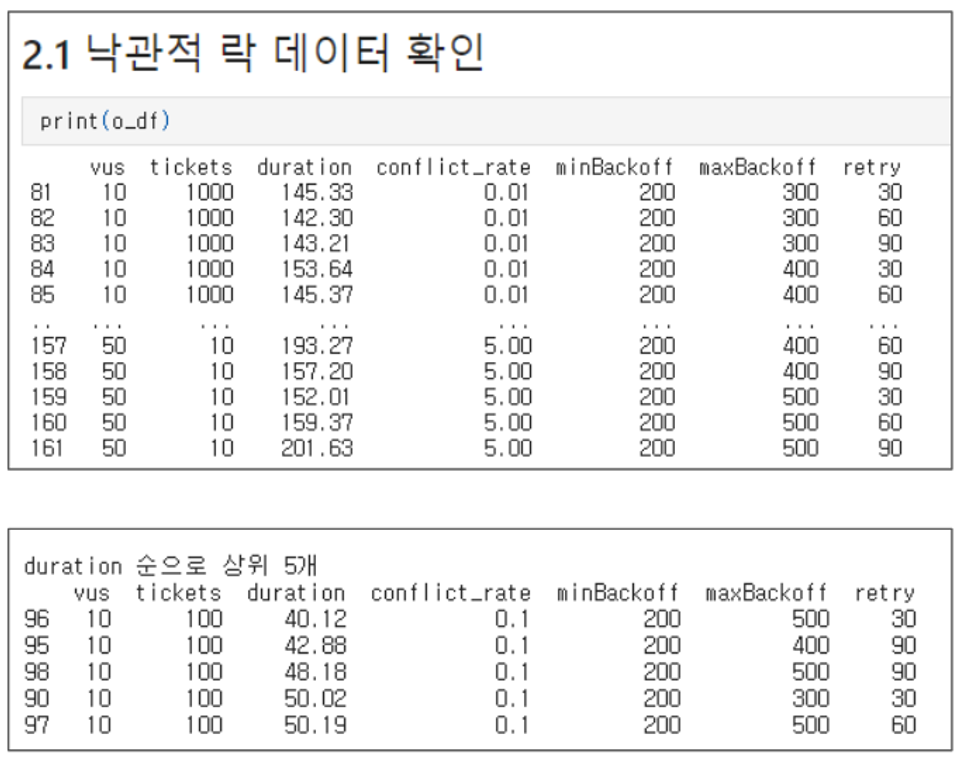
낙관적 락의 실행 결과입니다.
두번째 그림의 결과로부터 도출해낸 결론은 다음과 같습니다
- Retry 값은 일정 수치 이상일 경우, duration에 영향을 주지 않는다
- 하지만 높은 경합 상황에서 지나치게 낮은 retry 값은 성공률에 영향을 줄 것입니다
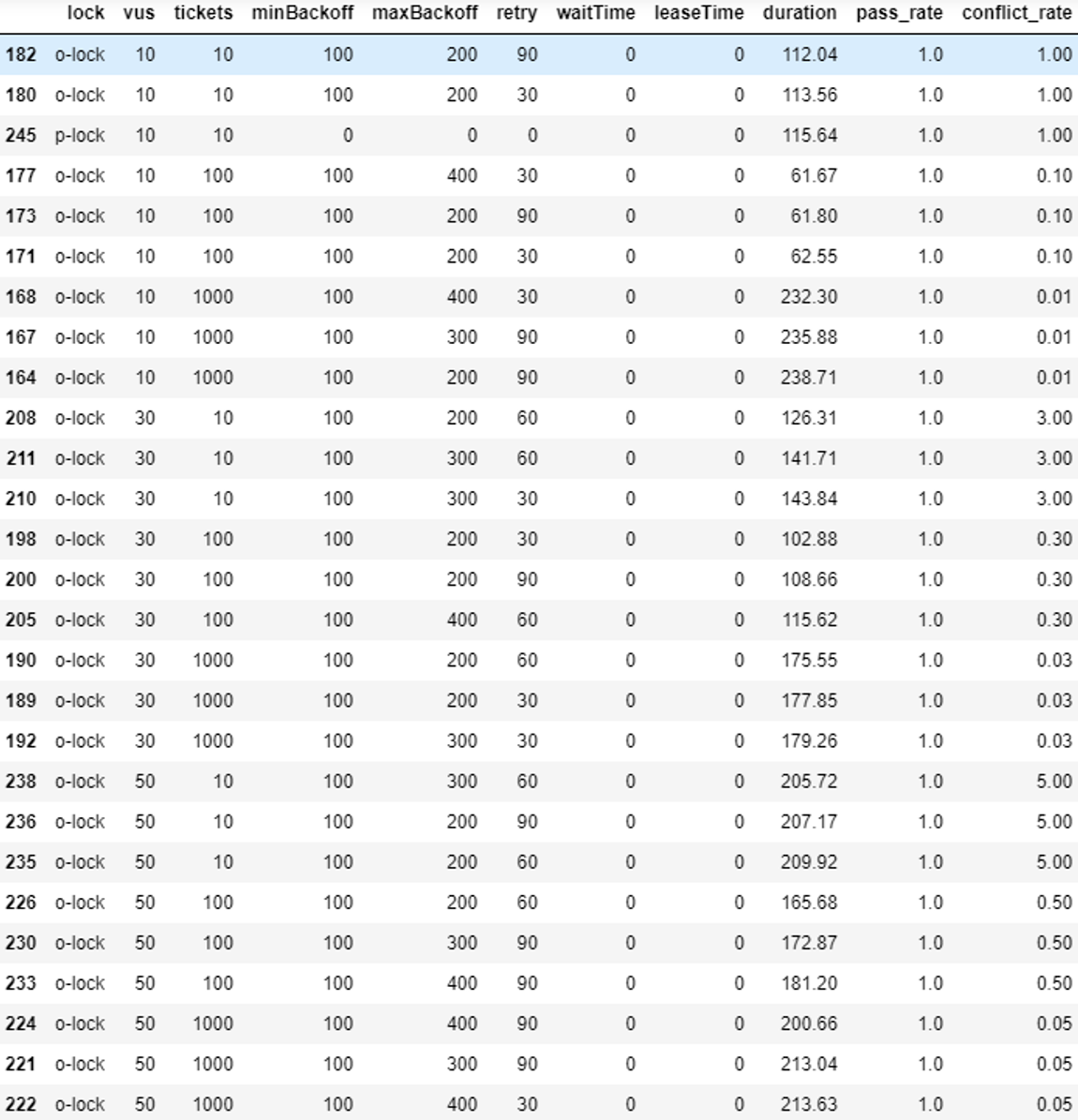
분산 락
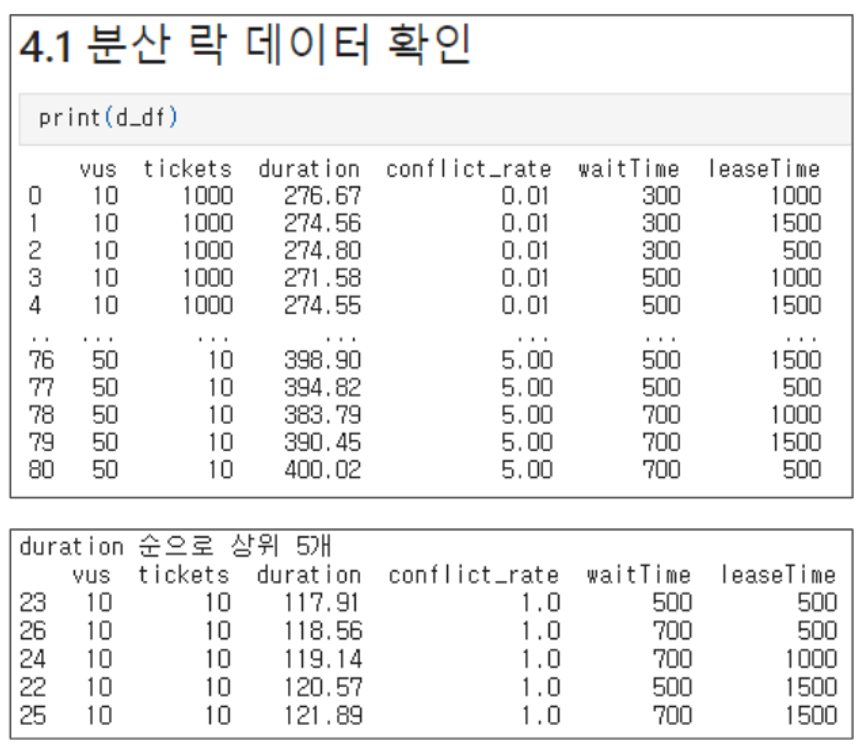
전체적으로 분산락의 duration값은 waitTime과 경합도에 정비례하는 경향을 보입니다.
추가적으로, 전체적인 duration값은 100이상을 넘는, 낙관적 락과 비관적 락에 비해 더 높은 값을 갖는 것을 관찰할 수 있습니다.
분산 락에서는 하나 더 추가적으로 고려해야할 지표가 있습니다.
전체 요청수를 VUS 수와 TICKET 수 중 더 낮은 값으로 나눈 비율을 의미하는 “성공률” 입니다.
결과에서는 두가지 특징을 관찰할 수 있습니다.
- 경합도가 증가할수록 성공률은 낮아진다 어찌보면 당연한 이야기입니다.
- 동일 조건에서는 waitTime (락을 기다리는 시간) 이 높을수록 성공률이 높다 waitTime을 모두 소모하면 tryLock 함수가 실패를 반환하기 때문에 이 역시 자명합니다. 다만, 동일한 조건 하에서 leaseTime 값에 따른 변화는 매우 적었습니다.
- waitTime을 증가시키면 성공률은 증가하지만, duration값 또한 증가한다
- 일종의 트레이드오프를 나타냅니다.
종합
전체 데이터에 대한 통계 결과입니다.
대부분의 케이스에서 낙관적 락이 더 우월한 성능을 보이는것을 관찰할 수 있습니다.
VUS와 TICKET 개수에 따라 묶은 케이스들에서도 낙관적 락이 가장 빠른 성능을 보였습니다.
결론
실험 결과들을 정리하도록 하겠습니다.
- 낮은 경합도 조건에서는 낙관적 락이 유리하다
- 초기 가정을 긍정합니다.
- 분산락은 낙관적 락과 비관적 락과 비교했을 때 성능이 좋지 않다.
- 정합성을 보장해야하는 티케팅 시스템에서 가장 중요한 지표인 성공률과 왕복시간(duration)이 좋지 않았습니다.
- 성공률을 높이기 위해서는 waitTime을 증가시켜야 하지만, 왕복시간이 증가합니다.
그래서 분산락은 쓸모없다?
그렇다면 분산 락은 쓸모가 없는것일까요?
그렇지 않습니다.
높은 경합 상황에서 다수의 서버를 동기화 시켜야 하는 경우,
작업 수행 시간 자체가 훨씬 길 경우 등에서는 더 유리한 경우가 분명 존재합니다.
항상 나오는 이야기지만,
트레이드오프를 고려하여 적절하게 락 종류를 선택하고, 환경에 맞추어 값을 튜닝하시기 바랍니다.
부록
더 자세한 데이터 분석의 결과는 팀원 임채윤님의 개인 블로그에서 확인하실 수 있습니다
댓글남기기