RAG
서론
AI 기술의 등장은 ~
회사들 또한 마찬가지로 AX라는 키워드를 내세우며 상품 및 가치창출에 활용하려는 ~
하지만 이러한 기조와는 반대로 실제 업무에서 AI를 실제 업무에 활용하는것은 불가능에 가까웠음
이유는 회사 업무의 많은 부분은 도메인 지식을 기반으로 운영되고, 실제 개발 업무 또한 마찬가지임
이와 같은 환경에서 상용화된 ChatGPT, Claude와 같은 AI 도구를 이용하더라도 어디까지나 일반적인 정보들을 제공받을 수 있을 뿐임.
또한, 관련 정보를 입력하는것 또한 보안 문제로 인해서 쉽지 않음.
이런 상황에서 활용할 수 있는게 RAG인데, 생각보다 등장한 지 꽤 시간이 지났지만 (2020), 오해하는 부분들도 많고
나처럼 그냥 “학습이 안된 최신 정보나 전용 데이터를 입력해서 부스팅시켜주는” 정도로 아는 경우가 있을꺼임
그래서 이번에 직접 실습을 통해 RAG에 대한 개념과 오해를 바로잡고, 성능을 강화시켜주는 몇가지 기법들을 확인하려고 함.
RAG
약어에 대해서 간단하게 살펴보면 다음과 같음
Retrieval : 어딘가에서 가져온다, 회수하다 Augmented : 증강된, 강화된 Generation : 생성하다
조금 더 파고들어보자
Retrieval - 어디서 뭘 가져오는거지?
짧게 말하면, 벡터로 임베딩된 텍스트를 벡터 DB에서 비교해서 가져옴.
벡터라고 하면 뭔가 물리학 관련 같고 낯선데, 단순하게 숫자의 집합이라고 생각해도 좋음 [0.1, 0.9, 0.0]
그리고 그 집합의 길이가 차원의 수임.
결국 이처럼 특정 데이터를 고정된 차원 수의 벡터로 표현하는걸 임베딩이라고 부름.
그리고 임베딩된 벡터들을 찾아서 비교해서 유사한 벡터를 찾아서 정보를 들고오는거임
Augmented: 증강된
증강시켜주는건 어디까지나 컨텍스트임
모델의 근본적인 논리력, 사고력을 강화시켜주는 개념이 아님
LLM과 RAG
RAG에 대한 중요한 점 중 하나는 RAG와 LLM이 상관이 없다는 것임.
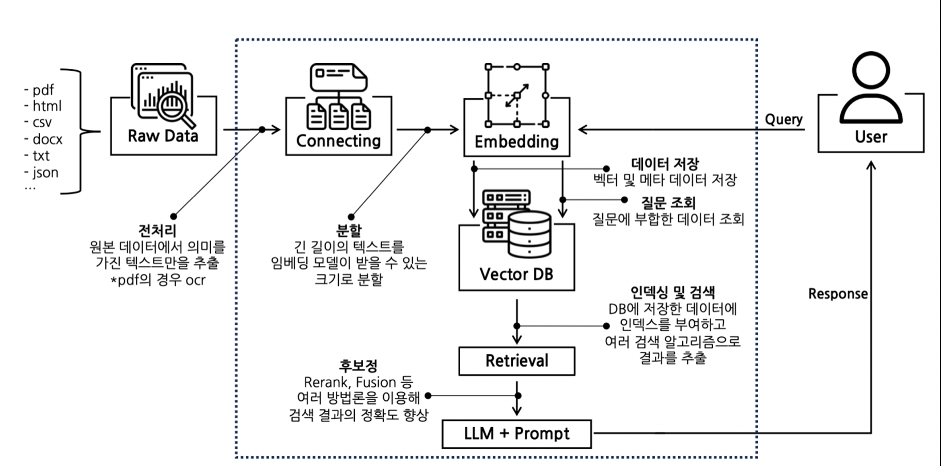
위 다이어그램에서 볼 수 있듯, 질의가 주어졌을 때 리트리버는 즉시 LLM에 전송하지 않음.
반드시 임베딩 - 벡터DB 유사도 검색이라는 과정을 거침.
이 과정의 결과를 통해서 강화된 컨텍스트를 가진
다른 질의를 만들고, 그 질의를 LLM에 던지는게 RAG의 원리임.
리트리버를 동작하는데에는 GPU 자원도 필요하지 않고, OpenAI의 API도 필요하지 않음.
심지어 병렬로 동작시켜도 LLM 자체의 성능에는 영향을 주지 않음.
실제로 확인해보자
이번 실습에서는 LM Studio를 활용할 예정임.
무료로 다양한 오픈소스 모델들을 테스트하는게 가능함.
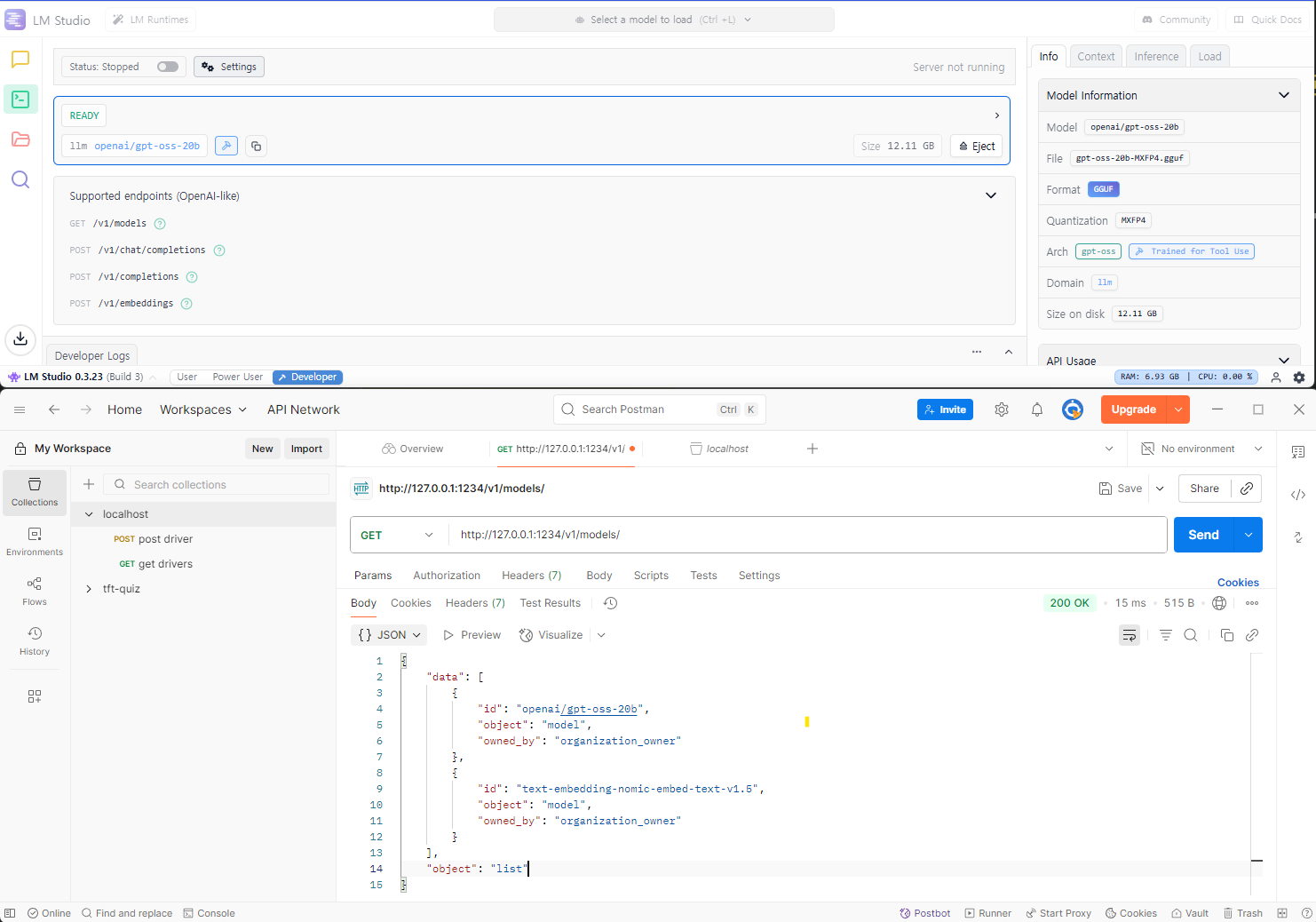
OpenAI의 API 형태를 지원하도록 서버를 구동시켜줌.
Postman 과 같은 http 테스팅 도구를 통해서 AI 모델과 통신이 가능함.
모델로는 gpt-oss-20b를 사용했음.
Raw 모델
# ---------- LLM & 체인 ----------
def build_chain(vectordb: FAISS, k: int) -> Tuple[ChatOpenAI, RetrievalQA]:
llm = ChatOpenAI(
model=CHAT_MODEL,
openai_api_key=API_KEY,
openai_api_base=BASE_URL,
temperature=0.0,
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectordb.as_retriever(search_kwargs={"k": k}),
return_source_documents=True,
chain_type="stuff",
)
return llm, qa_chain
def run_plain(llm: ChatOpenAI, question: str) -> str:
return llm.invoke(question).content
def main():
args = parse_args()
doc_path = Path(args.doc)
print(run_plain(llm, args.question), end="\n\n")
질의는 다음과 같이 구성했음
python main.py -q “In league of legends, is there a particular example where red side is at a disadvantage? Answer in a concise manner with maximum of 3 sentences” –preview

결과는 다음과 같이 나타났음

해당 이슈가 발견된 것은 비교적 최근이었기 때문에, LLM 모델은 알고있는 지식 내에서만 대답하고, 기대한 내용을 이끌어내지 못하는 모습을 보임
RAG 적용
이번에는 RAG를 적용해서 응답을 생성해보도록 하겠음.
가장 최근 리그 오브 레전드 패치노트를 policy.txt 라는 텍스트로 입력하였음
# ---------- LM Studio Embeddings (한 건씩) + 동시성 ----------
class LMStudioEmbeddings(Embeddings):
def __init__(self, model: str, base_url: str, api_key: str, timeout: int = 60, workers: int = 4):
self.model = model
self.base_url = base_url.rstrip("/")
self.api_key = api_key
self.timeout = timeout
self._headers = {"Authorization": f"Bearer {self.api_key}"}
self.workers = max(1, workers)
def _embed_one(self, text: str) -> List[float]:
url = f"{self.base_url}/embeddings"
payload = {"model": self.model, "input": text}
r = requests.post(url, headers=self._headers, json=payload, timeout=self.timeout)
r.raise_for_status()
return r.json()["data"][0]["embedding"]
def embed_query(self, text: str) -> List[float]:
return self._embed_one(text)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
# 병렬 임베딩(로컬 자원과 LM Studio 설정에 맞게 workers 조절)
results = [None] * len(texts)
with ThreadPoolExecutor(max_workers=self.workers) as ex:
futs = {ex.submit(self._embed_one, t): i for i, t in enumerate(texts)}
for f in as_completed(futs):
i = futs[f]
results[i] = f.result()
return results
def main():
args = parse_args()
doc_path = Path(args.doc)
# 강제 재빌드 옵션 시 manifest 지우기
if args.rebuild and MANIFEST_PATH.exists():
MANIFEST_PATH.unlink(missing_ok=True)
# 인덱스 로드/생성
vectordb, embeddings, _ = build_or_load_index(
doc_path=doc_path,
chunk_size=args.chunk_size,
overlap=args.overlap,
k=args.k,
workers=args.workers
)
llm, qa_chain = build_chain(vectordb, k=args.k)
preview_augmented_prompt(qa_chain, args.question, k=args.k)
추가적으로, 관련 컨텍스트를 리트리버가 불러온 결과를 확인하기 위해서 preview_augmented_prompt라는 함수를 구성함
def preview_augmented_prompt(qa_chain: RetrievalQA, question: str, k: int = 2) -> List[Document]:
docs = qa_chain.retriever.get_relevant_documents(question)
context_str = "\n\n---\n\n".join(d.page_content for d in docs)
prompt = qa_chain.combine_documents_chain.llm_chain.prompt
messages = prompt.format_messages(context=context_str, question=question)
print("\n====[ Augmented Chat Messages Preview ]====")
for m in messages:
role = getattr(m, "type", "human").upper()
print(f"\n[{role}]\n{m.content}")
return docs
전체 코드는 여기서 확인할 수 있음.
결과
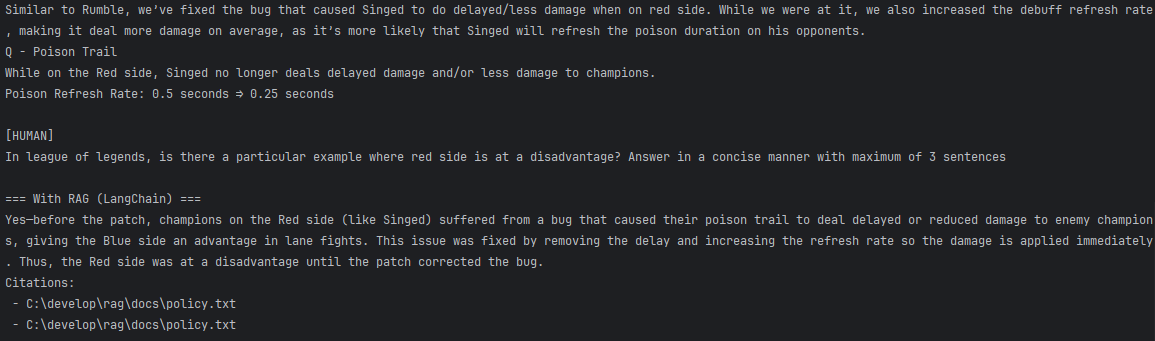
원하는 결과를 생성했고, 관련된 컨텍스트도 정확하게 추출한 결과를 관찰할 수 있음.
생각해보기
아마 지금까지 GPT 등 AI를 활용한 사람들은 만족스러운 관련 내용을 찾지 못했을 때, 웹사이트 링크를 넣거나, PDF 등 실제 자료를 주입해서 원하는 대답을 이끌어낸 적이 많을 꺼임.
이 이유는 GPT 자체가 자체 RAG 모델을 내장하고 있기 때문임.
하지만 GPT의 특성상 벡터 DB의 크기나 차원수는 우리가 커스터마이징 할 수도 없으며, 관련 컨텍스트가 커질수록
응답 속도가 느려지고 렉이 걸리는 현상이 발생함.
실제로 컨텍스트의 크기가 커질수록 응답의 품질은 낮아진다는 연구 결과도 존재함.
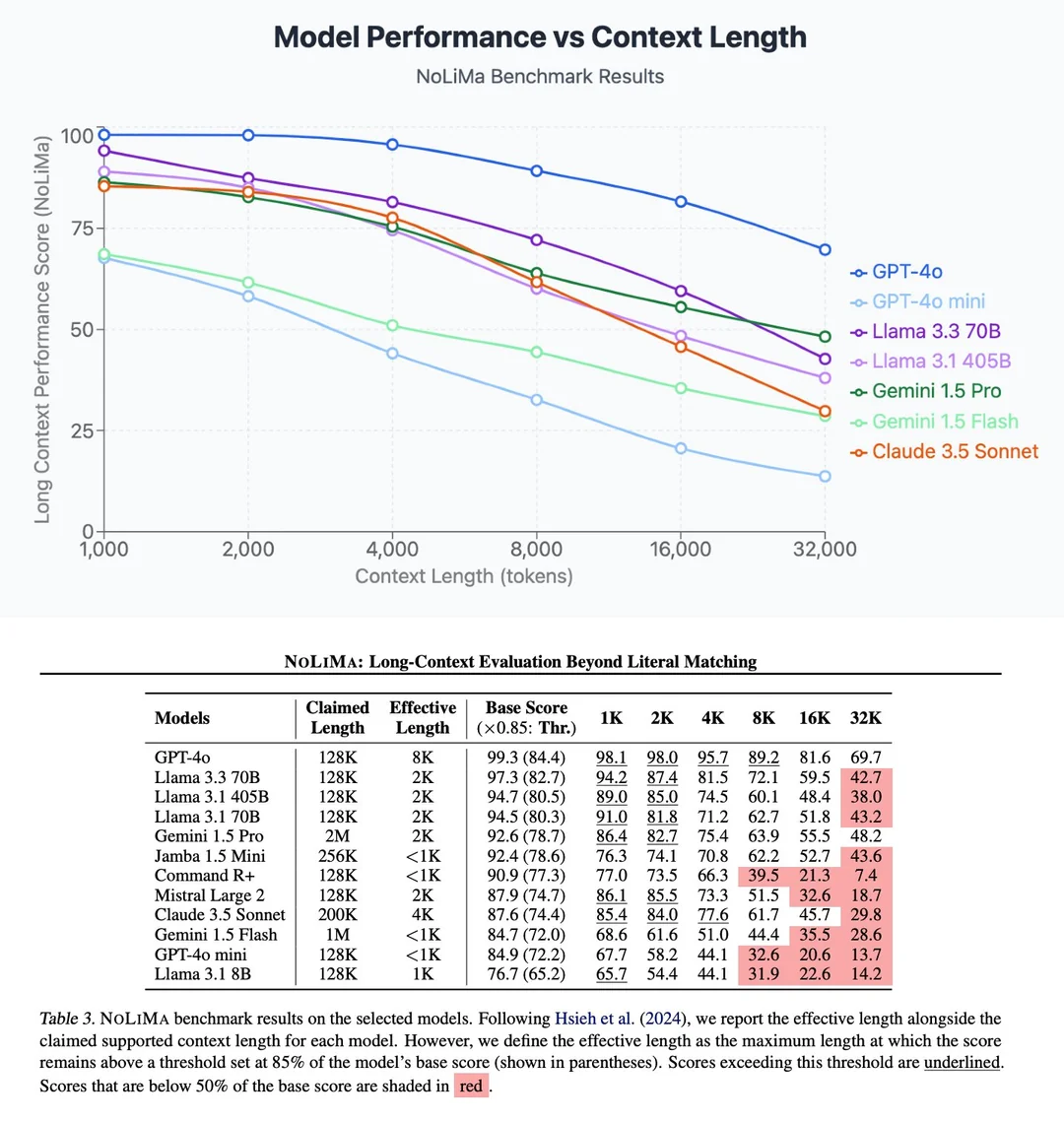
따라서 무작정 컨텍스트를 늘린다고 좋은것이 아니라는 거임.
이 문제를 회피하기 위해서 Sliding Context Window라는 기법을 사용하기도 함.
그래서 자체 RAG 또는 AI 업무 활용을 생각하고 있다면 우리는 단순히 200페이지 PDF를 업로드하는게 아니라
리트리버 입장에서 더 유사도를 검색하기 쉬운 형태로 데이터를 쌓는것이 중요하다는 거임.
그 기법으로 하나를 소개해보겠음
질의 분해 기법
우리가 갖고 있는 대부분의 정보는
댓글남기기